

Introduction
In the field of data science, particularly in the development and deployment of Artificial Neural Networks (ANNs), understanding the optimal network configuration is crucial for model performance. This blog explores the implementation and impacts of varying complexities in an ANN Regressor designed for one-dimensional input and output datasets, focusing on both a basic linear regression model and an ANN with a single hidden layer.
ANN Configurations and Implementations
The ANN Regressor was structured to examine two primary configurations:
- Linear Regressor: A basic model with no hidden layers, serving as a baseline.
- ANN with Single Hidden Layer: A more complex model employing 32 hidden units with a Sigmoid activation function.
Both models utilized stochastic learning for weight updates and were trained with a learning rate of 0.0011 over 1000 epochs. Key to this analysis was the use of data normalization and a comprehensive weight initialization strategy, which helped in avoiding early saturation of the activation function.
Implementation Highlights
- Learning Rate: Set at 0.0011 to balance between convergence speed and training stability.
- Weight Initialization: Uniformly distributed within [-1, 1].
- Epochs and Stopping Criterion: Training was halted after 1000 epochs based on observed loss plateaus.
Effects of Network Complexity
The core of our exploration was how different complexities, measured by the number of hidden units, affected the ANN’s ability to generalize. The findings indicated:
- A linear model (0 hidden units) was unable to capture the non-linear trends in the data, leading to substantial underfitting.
- Low complexity models (2-8 hidden units) adapted better to the data’s curvature, significantly enhancing the model fit without overfitting.
- Higher complexity models (16 and 32 hidden units) showed tendencies to overfit, closely following noise and potentially harming the model’s ability to generalize to new data.
Visual Analysis
Here are a series of plots showing the regression performance across these configurations, clearly illustrating the underfitting and overfitting phenomena.
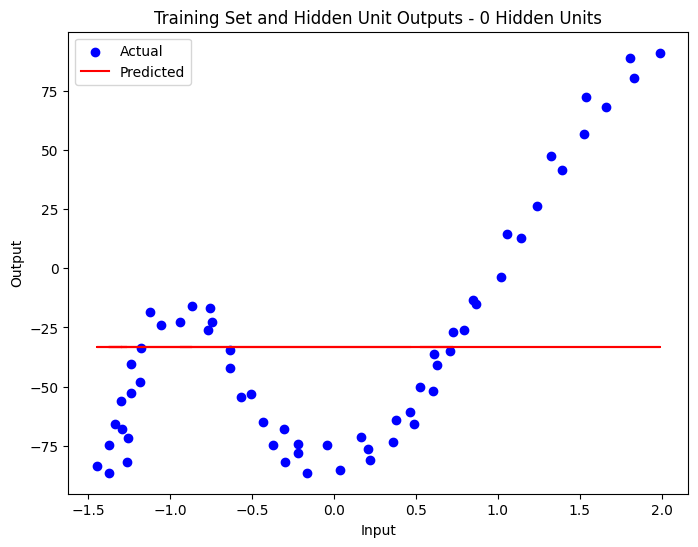
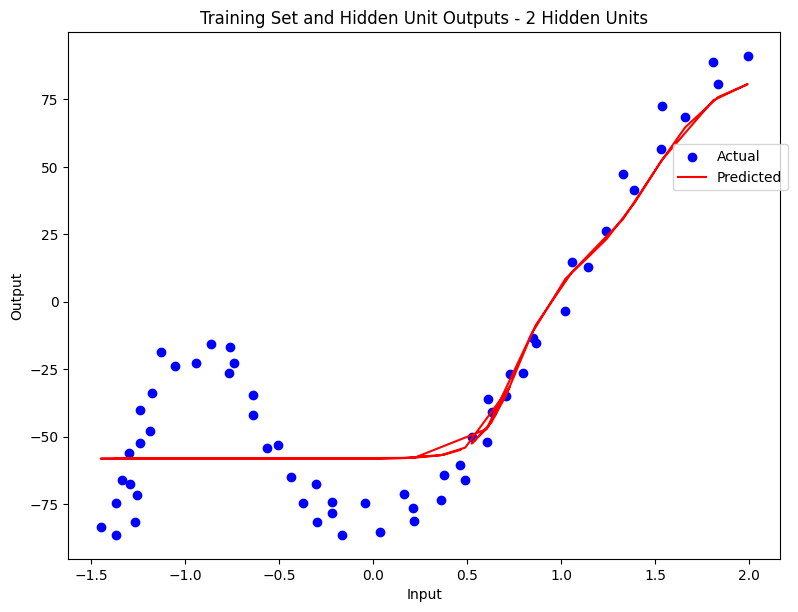
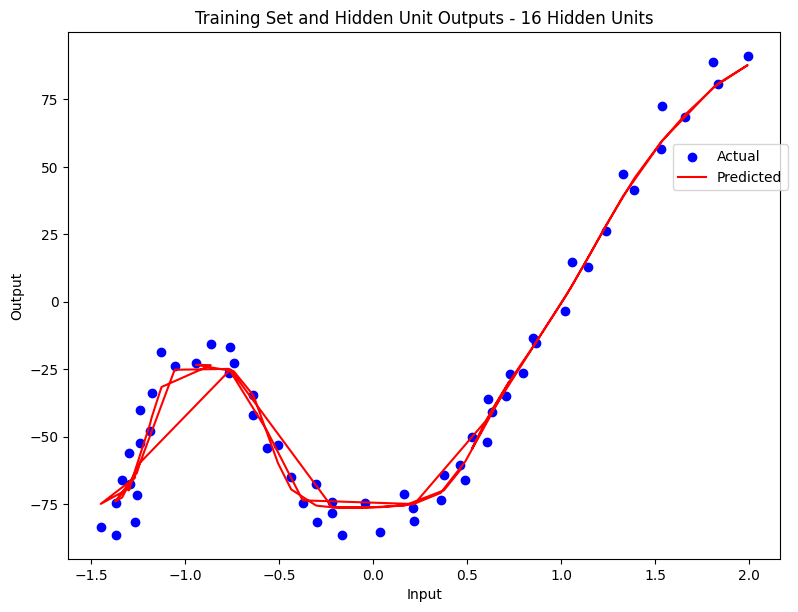
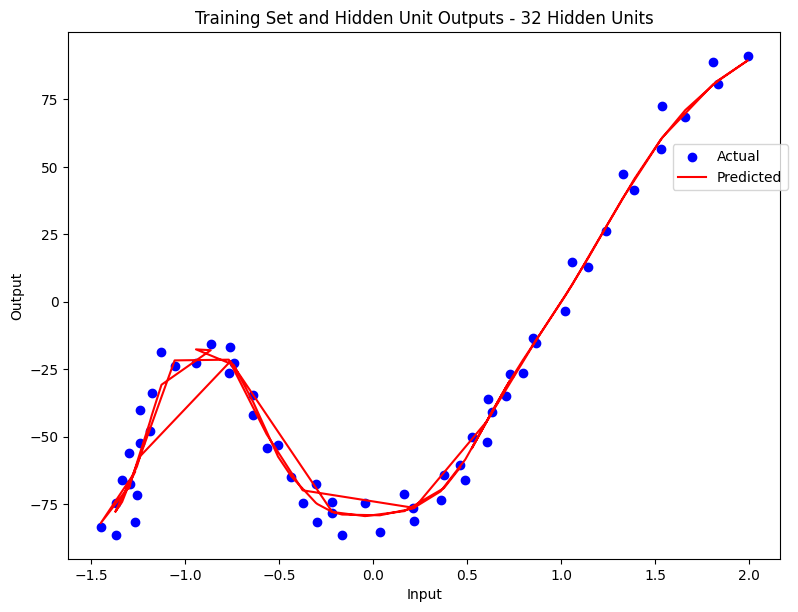
Conclusion
There exists a delicate balance between underfitting and overfitting in ANNs. The progression from a simple linear regressor to an ANN with 32 hidden units showcased how increased complexity can initially improve learning and test performance but may eventually lead to overfitting.